Spring Batch 적용기
intro
현재 진행 중인 프로젝트 로직 중 매일 자정마다 통계 테이블을 갱신해야 하는 로직이 있다. 해당 로직을 구현하기 위해 Spring Batch를 이용해보려고 한다.
Spring Batch를 선택한 이유는, 대용량 데이터를 처리하기 위함과, 현재 사용 중인 프레임워크가 Spring Boot이기 때문이다. (그냥 한번 공부해서 사용해보고 싶은 이유도 있다ㅎㅎ)
그리고 해당 로직이 실행되며 예외가 발생할 경우, 어떠한 단위 기준(chunk)으로 재시도하거나 예외를 처리할 수 있다고 들었다. 또한 해당 단위(chunk)의 로직이 실패할 경우 다음 단위(chunk)의 로직으로 넘어가게 할 수도 있다고 한다.
이러한 이유들로 Spring Batch를 선택했고, 공부하여 프로젝트에 적용해보고자 한다!
Spring Batch란?
Spring Batch는 대량의 데이터 처리를 위한 경량화된 프레임워크로, 반복적인 작업을 수행하는 일괄 처리(Batch Processing) 작업을 효율적으로 처리할 수 있는 기능을 제공한다. 대용량 데이터 처리나 주기적인 업무 처리 등을 효율적으로 처리할 수 있고, 대용량 데이터 처리에 적합한 분산 방식의 처리를 지원한다.
Spring Batch의 특징
대용량 데이터 처리
데이터를 읽고 처리하고 저장하는 작업을 청크(chunk) 단위로 나누어 처리한다. 대량의 데이터를 효율적으로 처리할 수 있으며, 메모리 사용을 최소화할 수 있다.
또한 배치 작업은 여러 개의 스텝(step)으로 구성될 수 있으며, 각 스텝은 독립적으로 실행되고, 데이터의 읽기, 처리, 쓰기를 담당한다.
재시도 및 예외 처리
배치 작업이 실패할 경우, 재시도 정책을 설정하여 특정 횟수만큼 재시도할 수 있다. 또한 특정 예외가 발생했을 때, 예외를 처리할 수 있는 다양한 방법을 제공한다.
트랜잭션 관리
배치 작업 중 발생할 수 있는 트랜잭션을 관리한다. 각 청크(chuck) 처리 단위가 하나의 트랜잭션으로 묶여 데이터의 일관성을 유지한다. 또한 실패한 트랜잭션을 롤백하여 데이터의 무결성을 보장한다.
스케줄링과 통합 가능
Spring Batch 자체로 스케줄링 기능이 포함되어있지 않지만 Spring Scheduler 또는 Quartz와 통합하여 배치 작업을 주기적으로 실행할 수 있다. 나는 Spring Batch + Spring Scheduler를 통합하여 사용하였다.
데이터 읽기 및 쓰기 지원
다양한 데이터 소스를 지원한다.(JDBC, JPA, Hibernate 등) 나는 현재 ORM으로 Spring Data Jpa를 사용 중이기 때문에 JPA 데이터 소스를 이용하여 배치를 구성하였다.
메타 테이블을 이용한 모니터링
배치 작업의 상태를 관리하기 위한 메타 데이터를 저장하는 테이블이 존재한다. 배치 작업이 수행되면 자동으로 생성된 테이블들에 값들이 채워진다. 해당 데이터들을 이용하면 로깅 시 유용하며, 로깅을 하지 않더라도 테이블을 열어 배치 실행 여부, 수행시간 등을 확인할 수 있다.
Spring Batch 사용하기
의존성 주입
implementation 'org.springframework.boot:spring-boot-starter-batch'
application.yml
spring:
batch:
jdbc:
initialize-schema: always
job:
enabled: false
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/${DATABASE_NAME}
username: ${MYSQL_USERNAME}
password: ${MYSQL_PASSWORD}
[ intialize-schema ]
해당 설정은 Spring Batch의 메타 테이블을 데이터베이스에서 초기화하는 방법을 지정하는 설정이다.
- always: 애플리케이션이 시작될 때마다 메타데이터 테이블을 항상 초기화함
- never: 애플리케이션이 시작될 때마다 메타데이터 테이블을 초기화하지 않음
- embedded: 내장형 데이터베이스 사용 시에만 초기화를 수행함
나는 현재 mysql을 서버 db로 사용 중이기에 해당 데이터베이스에 메타테이블이 생성되게 하였고, 애플리케이션이 시작될 때마다 메타데이터 테이블을 초기화하기 위해 always로 설정하였다.
[ Spring batch job enabled ]
해당 설정은 애플리케이션 실행 시에 배치 작업 자동 실행 여부 설정이다.
나는 스케줄러를 이용하여 배치를 실행시키므로 해당 설정을 false 처리하였다.
패키지 구조

패키지 구조는 위의 사진처럼 구성하였다.
다른 개발자들의 블로그 글들을 참고해 보니 대부분 test용으로 만들어서인지 job과 step을 한 클래스에 넣어서 로직을 구성하였다.
실제 프로젝트에 해당 로직을 하나의 파일로 관리해 보니 가독성이 매우 떨어졌다. 이대로는 유지보수가 힘들겠다는 생각이 들어서 위와 같이 job, step, listener로 분리하였다.
나의 프로젝트에서는 배치처리가 스케줄러와 함께 이루어지고 있기 때문에 job의 경우 일, 월, 년의 job으로 분리하여 구성하였다.
Listener


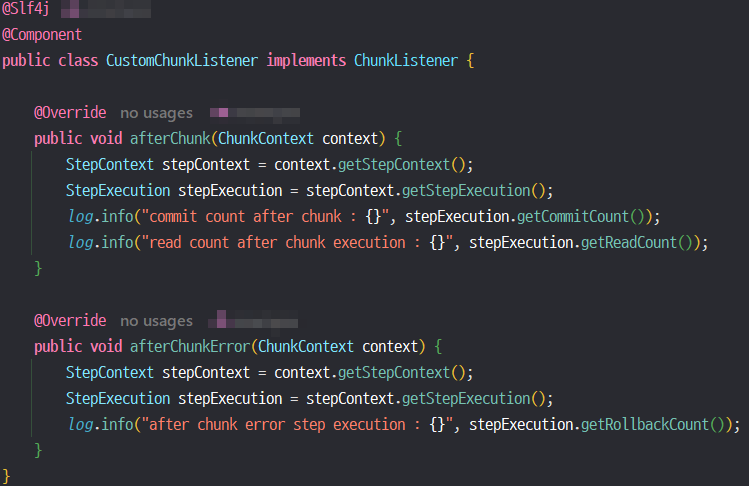
Listener는 배치 작업을 실행 과정에서 특정 이벤트가 발생할 때 이를 감지하고 대응할 수 있도록 돕는 인터페이스이다. Spring Batch는 여러 종류의 Listener를 제공한다.
내 프로젝트의 경우 아직까지 리스너가 크게 필요는 없지만, 해당 Job 또는 Step의 시작 또는 종료, chunk 단위 트랜잭션 실행 시 발생한 에러 또는 진행상황을 간단하게 로그로 확인할 수 있도록 설정해 놓았다.
JobConfig
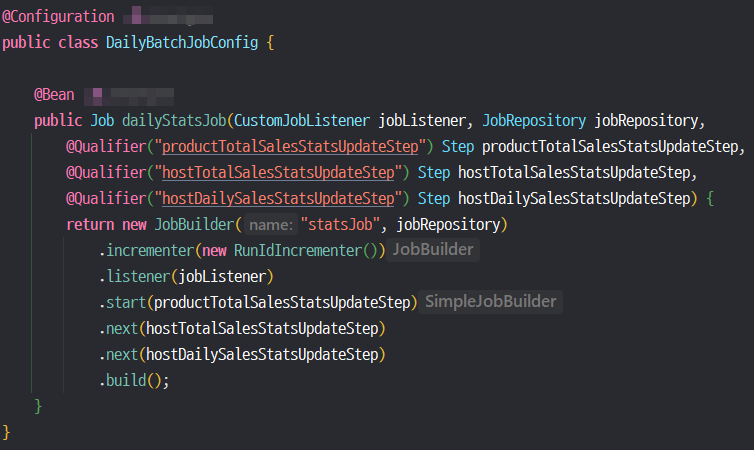
위의 Job은 매일 어떤 Step을 실행할 것인지가 설정되어 있다.
[ incrementer ]
해당 필드는 배치 작업 실행 시 JobParameters를 자동으로 증가시켜(마치 mysql의 auto increment처럼) 해당 job의 유일성을 보장한다. 나는 1씩 증가시키는 RunIdIncrementer를 사용하였는데 이 외에 유일성을 갖게 할 수 있는 Incrementer라면 모두 사용 가능하다.(사용자 정의 Incrementer 사용 가능)
[ listener ]
어떤 listener를 사용할지 설정한다.
[ start, next ]
start 필드의 step부터 next 필드의 step이 차례대로 진행된다.
StepConfig
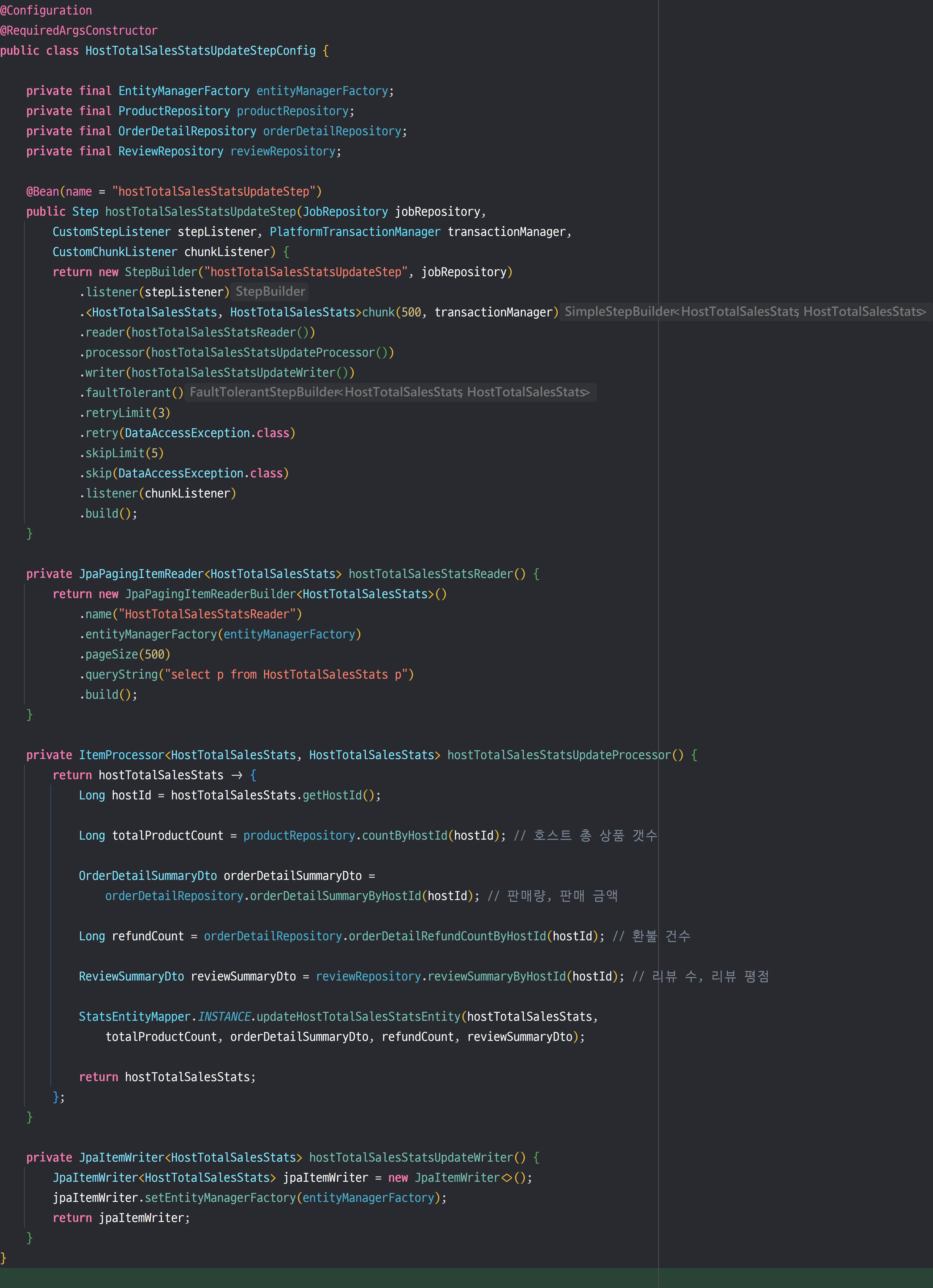
Step은 Chunk 단위 처리 방법과 Tasklet 처리 방법이 있다.
[ Tasklet 처리 방법 ]
Step 내에서 단일 작업 단위로 실행된다. 즉 하나의 트랜잭션 범위 내에서 실행된다는 의미이다. 그렇기 때문에 대용량의 데이터 처리 중 하나의 데이터가 문제가 생겨도 진행됐던 모든 작업들이 롤백될 수 있다. 따라서 롤백 시의 비용 또한 클 수 있으며 대용량 데이터 작업 시 성능 저하가 발생할 수 있다.
[ chunk 단위 처리 방법 ]
데이터를 chunk 단위로 나누어서 처리하는 방법이다. 각 청크는 독립적인 트랜잭션으로 처리되므로, 하나의 청크에서 오류가 발생하더라도 다른 청크는 영향을 받지 않는다. 따라서 부분 롤백이 가능하며, 데이터 처리 단위가 존재하므로 메모리에 모든 데이터를 올릴 필요가 없어서 메모리 사용량이 줄어든다.
나의 프로젝트에 Spring Batch 사용이유는 만 건 이상의 데이터를 처리하기 위함이므로 Tasklet 처리방식과는 맞지 않는다. 따라서 나는 chunk 단위 처리 방법을 사용하였다.
[ JpaPagingItemReader ]
해당 ItemReader는 대량의 데이터를 효율적으로 읽기 위해 페이징 방식을 사용한다. 따라서 배치 작업에서 한 번에 처리할 수 있는 데이터를 제어할 수 있다. 이 방식을 사용하여 메모리 사용량을 조절할 수 있다.
나의 프로젝트는 현재 JPA를 사용하고 있기 때문에 JpaPagingItemReader를 사용하여 효과적으로 데이터를 가져올 수 있었다. 또한 쿼리 작성 방법도 JPQL을 사용하므로 복잡한 쿼리를 좀 더 쉽게 접근할 수 있다.
[ ItemProcessor ]
ItemReader로부터 읽어온 데이터를 처리할 수 있는 핵심 로직을 구현할 수 있다. 위의 이미지처럼 메서드로 구현할 수도 있고, 인터페이스 구현 객체로도 구현이 가능하다.
[ JpaItemWriter ]
해당 ItemWriter는 JPA를 사용하여 데이터를 데이터베이스에 저장하는 데 사용되는 ItemWriter 구현체이다. ItemProcessor로부터 처리된 데이터를 데이터베이스에 저장하는 역할을 한다.
faultTolerant
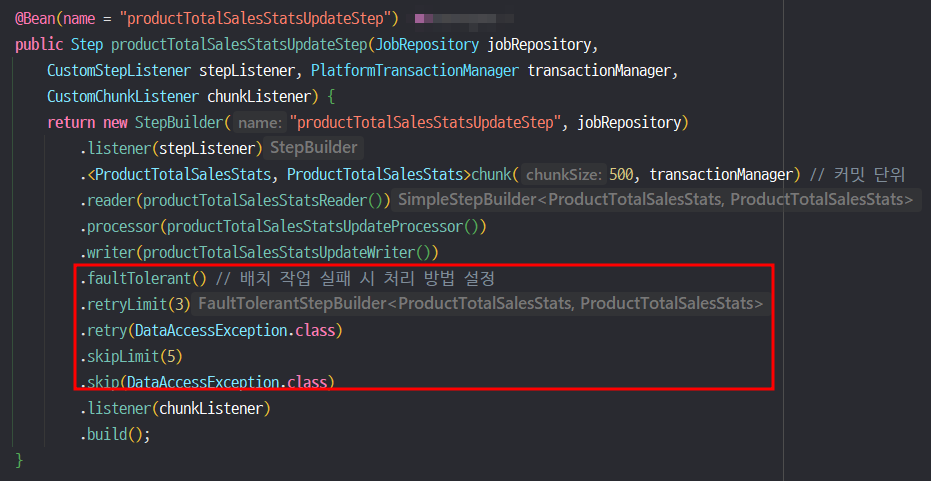
faultTolerant는 배치 작업이 실행 중 오류가 발생되어도 전체 작업이 실패하지 않고, 특정 방식으로 오류를 처리하거나 재시도할 수 있도록 한다. Step 정의 시 설정할 수 있고, StepBuilder를 사용하여 구성할 수 있다.
위의 사진처럼 faultTolerant()를 추가하며 설정 시작을 알린 후 아래에 메서드 체이닝 방식으로 재시도와 스킵 등을 설정할 수 있다.
위의 설정은 DataAccessException 예외가 발생할 경우 3회의 재시도를 거치고, 실패할 경우 5번의 skip을 허용한다는 설정이다.
chuck size와 page size
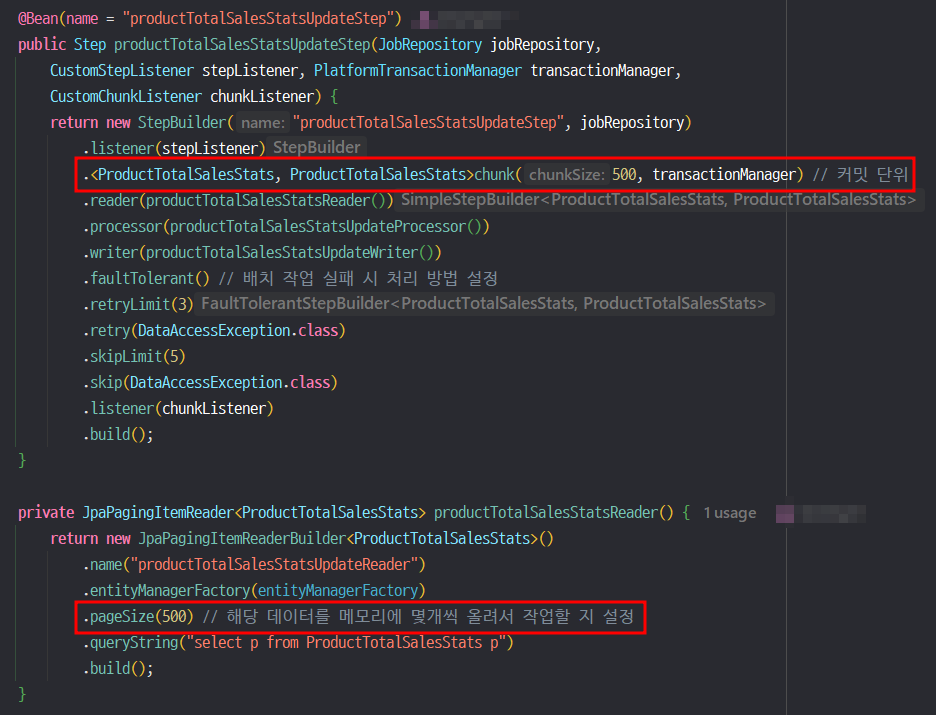
위의 이미지를 보면 chunk size와 page size 설정이 각각 따로 존재한다.
비슷한 개념인 것 같은데 왜 따로 존재하는지 궁금하여 알아보니, chunk size의 경우 커밋 단위를 뜻하고, page size는 메모리에 몇 개의 데이터를 올려서 작업할지를 설정하는 것이다.
예를 들면 chunk 단위가 500이고 page size가 1000일 경우, 1000개의 데이터를 메모리에 올려놓고 500개씩 작업을 한다는 이야기이다.
관련 글들을 찾아보니 chunk size와 page size를 똑같이 맞춰주는 것이 가장 효율적이라고 한다. 더미데이터를 이용하여 test를 해본 결과 500 이상의 데이터부터는 속도가 점점 감소하는 것으로 나타나고, 전체 작업 시간이 늘어나는 것으로 판단되어 chunk size와 page size를 500으로 설정하였다.
Spring Scheduler와 Spring Batch
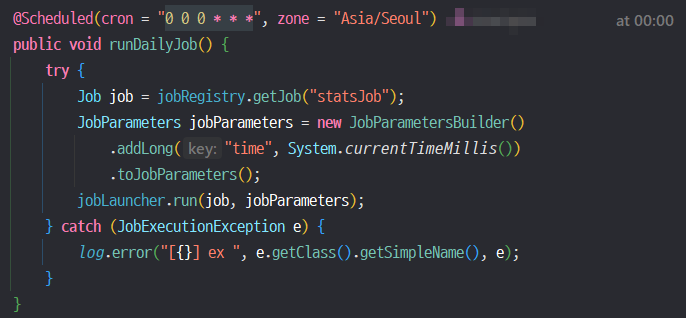
설정된 Batch Job을 실행하는 코드이다. 해당 코드는 "statsJob"을 매일 자정에 실행시키는 코드이다.
결론
처음에 Spring Batch와 Spring Scheduler를 공부하면서 이 두 기술이 비슷한 기능을 제공한다고 생각했지만, 실제로는 각각 전혀 다른 역할과 목적을 가지고 있다는 것을 알게 되었다.
Spring Batch와 Spring Scheduler의 차이점
Spring Batch는 대량의 데이터를 효율적으로 처리하는 데 중점을 둔 프레임워크이다. 데이터의 읽기, 처리, 저장을 체계적으로 관리하여 반복 작업을 전략화할 수 있다. 이와 달리, Spring Scheduler는 주기적으로 또는 특정 시점에 작업을 자동으로 실행하는 기능을 제공한다. 이는 주기적인 작업 스케줄링이나 정기적인 데이터 처리 작업에 적합하다.
현재의 문제와 성능 이슈
현재 한 개의 step당 데이터 10,000건을 처리하는 데 약 15분이 소요되고 있다. 이는 주로 처리 로직의 복잡성과 여러 테이블 간의 조인 작업에서 비롯된 것으로 보인다. 통계 데이터 갱신 로직이 복잡하고, 많은 계산을 요구하는 데다가 다양한 테이블을 사용하다 보니 처리 시간이 길어질 수 있다. 정확히 어떤 부분에서 속도 문제가 발생하는지는 아직 명확히 파악하지 못했다.
이러한 성능 문제를 해결하기 위해, 데이터 처리 과정을 최적화하거나, 쿼리 성능을 개선하는 등의 노력이 필요할 것 같다. 이와 관련된 문제 분석 및 해결 방안은 별도로 블로그에 자세히 정리할 예정이다.
참고
https://velog.io/@kjh48001/Spring-Batch-공식문서를-읽고-그림으로-정리하자-1.-스프링-배치-소개
https://velog.io/@chrkb1569/Spring-Batch-Spring-Batch-전체-동작-과정-알아보기
https://github.com/spring-projects/spring-batch/wiki/Spring-Batch-5.0-Migration-Guide#dependencies-upgrade
https://tonylim.tistory.com/433
https://docs.spring.io/spring-batch/reference/index.html
https://oingdaddy.tistory.com/364